С хешированием мы сталкиваемся едва ли не на каждом шагу: при работе с браузером (список Web-ссылок), текстовым редактором и переводчиком (словарь), языками скриптов (Perl, Python, PHP и др.), компилятором (таблица символов).
В мире алгоритмов
С хешированием мы сталкиваемся едва ли не на каждом шагу: при работе с браузером (список Web-ссылок), текстовым редактором и переводчиком (словарь), языками скриптов (Perl, Python, PHP и др.), компилятором (таблица символов). По словам Брайана Кернигана, это «одно из величайших изобретений информатики». Заглядывая в адресную книгу, энциклопедию, алфавитный указатель, мы даже не задумываемся, что упорядочение по алфавиту является не чем иным, как хешированием.
Хеширование есть разбиение множества ключей (однозначно характеризующих элементы хранения и представленных, как правило, в виде текстовых строк или чисел) на непересекающиеся подмножества (наборы элементов), обладающие определенным свойством. Это свойство описывается функцией хеширования, или хеш-функцией, и называется хеш-адресом. Решение обратной задачи возложено на хеш-структуры (хеш-таблицы): по хеш-адресу они обеспечивают быстрый доступ к нужному элементу. В идеале для задач поиска хеш-адрес должен быть уникальным, чтобы за одно обращение получить доступ к элементу, характеризуемому заданным ключом (совершенная хеш-функция). Однако на практике идеал приходится заменять компромиссом и исходить из того, что получающиеся наборы с одинаковым хеш-адресом содержат более одного элемента.
Термин «хеширование» (hashing) в печатных работах по программированию появился сравнительно недавно (1967 г. [1]), хотя сам механизм был известен и ранее. Глагол «hash» в английском языке означает «рубить, крошить», т. е. создавать этакий «винегрет». Для русского языка академиком А.П. Ершовым [2] был предложен достаточно удачный эквивалент — «расстановка», созвучный с родственными понятиями комбинаторики, такими как «подстановка» и «перестановка». Однако пока он не прижился.
Как отмечает Дональд Кнут [3], идея хеширования впервые была высказана Г.П. Ланом при создании внутреннего меморандума IBM в январе 1953 г. с предложением использовать для разрешения коллизий хеш-адресов метод цепочек. В открытой печати хеширование впервые было описано Арнольдом Думи (1956), указавшим, что в качестве хеш-адреса удобно использовать остаток от деления на простое число. Подход к хешированию, отличный от метода цепочек, был предложен А.П. Ершовым (1957), который разработал и описал метод линейной открытой адресации. Среди других исследований можно отметить работы Петерсона (1957, [4]) и Морриса (1968, [5]). В первой реализовывался класс методов с открытой адресацией при работе с большими файлами, а во второй давался обширный обзор по хешированию и вводился термин «рассеянная память» (scatter storage).
Массивы — предшественники хеш-структур
Одна из важных задач, решаемых в программировании,— это обеспечение быстрого (прямого) доступа к данным по некоему коду (индексу, адресу). Неудивительно, что решающий эту задачу массив стал одним из главных строительных блоков, превосходя по использованию списки, которые определяют последовательный доступ к элементам. В математике массиву соответствуют понятия вектор (в одномерном случае) и матрица (в двумерном).
Как известно, массив задает отображение (A) множества индексов (I) на множество элементов (E), т. е. A: I — E. Массив позволяет по индексу быстро найти требуемый элемент. Хеширование решает в точности такую же задачу. Однако здесь уже в роли индекса выступает хеш-адрес, который определяется как значение некоей хеш-функции, применяемой к уникальному ключу. В этом смысле хеш-структуры можно рассматривать как обобщение массива.
В программировании зависимость между индексом и значением записывается в виде: A = ARRAY I OF E. В роли индексирующего типа (I) обычно выбирается конкретный диапазон значений из целочисленного типа (хотя в общем случае в их роли могут выступать так называемые скалярные типы, т. е. булев тип, перечисления, множества и др.). Ну а элементы массива в зависимости от языка программирования могут быть любыми, начиная от битов, чисел и указателей (ссылок) и заканчивая составными типами произвольной глубины.
То, что массив задает функцию отображения, в языке Ада подчеркивается даже на уровне синтаксиса. Например, при появлении в тексте программы записи вида «a(i)» трудно с ходу сказать, идет ли это обращение к i-му элементу массива «a» или же просто вызывается функция «a» с параметром «i».
Выделяют два разных вида массивов: одномерные (наиболее общий случай) и многомерные (на каждом слое адресации используется массив фиксированной структуры). Во втором случае есть и особый подвид: ступенчатые массивы (jagged arrays). Они встречаются, в частности, в языке C# в том случае, когда на каждом слое адресации используется массив переменной структуры. Иначе говоря, здесь мы имеем дело с массивом разных массивов. В других языках такая конструкция легко описывается массивом разнородных указателей (каждый указывает на массив своей структуры), что фактически определяет массив списков.
Интересно, что Н. Вирт после многих лет использования в своих языках (Паскаль, Модула-2) в качестве индексирующего типа разных скалярных типов пришел к выводу, что лаконичное решение, воплощенное в языке Си (а точнее, унаследованное в Си от языков BCPL и B), носит куда более практичный характер. И в своих новых языках Оберон и Оберон-2 он отказался от идей Паскаля и ограничился заданием размера массива (количества индексируемых элементов), т. е. определением для индексов диапазона 0...n—1, где n — это размер массива: A = ARRAY 16 OF E. Связано это с эффективностью реализации и с активным использованием в программировании элементов модулярной арифметики. В Обероне предопределенная функция MOD («x MOD n»), как и в математике, соответствует остатку от целочисленного деления «x» на «n». Как показывает опыт, использование 0 в качестве начального индекса удобно в подавляющем большинстве задач. Механизмы хеширования опираются точно на ту же основу.
Математика и программирование
Вспомним некоторые определения из курса элементарной математики. Отображением (f: A — B) множества A во множество B (функцией на A со значениями в B) называется правило, по которому каждому элементу множества A сопоставляется один или несколько элементов множества B. Отсюда следует, что отображения могут быть однозначными и многозначными в зависимости от того, имеет ли каждый прообраз в соответствии один или несколько образов. Однозначное отображение f: A— B называется сюръективным (сюръекцией), если f(A) = B. Это так называемое отображение «на». Отображение (в общем случае неоднозначное) называется инъективным, если образы различных прообразов различны (отображение «в»). Cюръективное и инъективное отображение называется биекцией.
Вот теперь, пользуясь этими понятиями, попробуем разобраться в природе хеширования. Итак, одномерные и многомерные массивы — это яркий пример сюръекции. Поэтому их можно назвать «сюръективными» массивами. Биекцию в общем случае они не задают, поскольку разным индексам (прообразам) могут соответствовать одни и те же значения (образы). Примером «биективного» массива может служить, например, соответствующим образом заполненный массив литер: ARRAY 256 OF CHAR.
В реальных задачах нередко возникают ситуации, когда не столько важно иметь однозначное соответствие между адресом и значением, сколько гарантию того, что одно и то же значение не может быть получено по разным адресам. А это и есть инъекция, реализуемая через хеширование. Следовательно, в случае хеширования значения хранятся в «инъективных» массивах разной структуры. Именно здесь проходит водораздел между разными схемами и методами хеширования. Именно отсюда и проистекают проблемы поиска оптимального баланса между пространством хранения и временем доступа.
Схемы хеширования
Традиционно принято выделять две схемы хеширования:
- хеширование с цепочками (со списками);
- хеширование с открытой адресацией.
В первом случае выбирается некая хеш-функция h(k) = i, где i трактуется как индекс в таблице списков t. Поскольку нельзя гарантировать, что не встретится двух разных ключей, которым соответствует один и тот же индекс i (конфликт, коллизия), такие «однородные» ключи просто помещаются в список, начинающийся в i-ячейке хеш-таблицы t (см. рисунок). Очевидно, что процесс заполнения хеш-таблицы будет достаточно простым, но при этом доступ к элементам потребует двух операций: вычисления индекса и поиска в соответствующем списке. Операции по занесению и поиску элементов при таком виде хеширования будут вестись в незамкнутом (открытом) пространстве памяти.
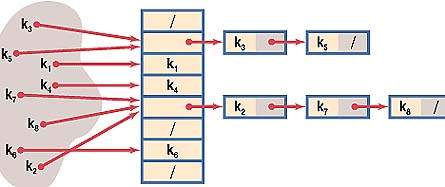
Отображение ключей путем хеширования с цепочками
Во втором случае все операции производятся в одном измерении, и таблица t является обычным одномерным массивом. Однако в этом случае подход к разрешению коллизий индексов иной: либо элементы с «однородными» ключами пытаются размещать в непосредственной близости от полученного индекса, либо осуществляют многократное хеширование (обычно двойное), когда для хорошего перемешивания последовательно применяется набор разных (взаимосвязанных) хеш-функций. Очевидно, что здесь и заполнение хеш-таблицы, и доступ к элементам будет весьма замысловатым. Хеш-адрес элемента с данным ключом как бы открыт: он постепенно уточняется. При этом все операции ведутся в замкнутом пространстве (в одномерном массиве).
Как нетрудно заметить, традиционная классификация методов хеширования может быть заменена другими: хеширование с цепочками можно относить по классификации Ахо, Хопкрофта и Ульмана [6] к так называемому «открытому» хешированию (в данной статье — к многомерному хешированию, поскольку при использовании списков речь идет о нескольких измерениях), а хеширование с открытой адресацией — к «закрытому» хешированию (одномерному).
Реализация хеш-таблиц
На практике нередко задача упрощается тем, что вместо пары «ключ—элемент» в хеш-таблицу достаточно заносить только ключи, поскольку ключ нередко совпадает с самим элементом (в случае текстовых строк и чисел). Если это не так, то необходимо хранить рядом и ссылки на соответствующие элементы.
Прежде чем рассматривать схемы и соответствующие им методы хеширования, давайте остановимся на спецификации модуля, в котором реализуются обсуждаемые ниже методы.
15.06.2001г
Мир ПК